Posted by Dom-Woodman
Occasionally, a problem will land on your desk that's a little out of the ordinary. Something where you don't have an easy answer. You go to your brain and your brain returns nothing.
These problems can’t be solved with a little bit of keyword research and basic technical configuration. These are the types of technical SEO problems where the rabbit hole goes deep.
The very nature of these situations defies a checklist, but it's useful to have one for the same reason we have them on planes: even the best of us can and will forget things, and a checklist will provvide you with places to dig.
Fancy some examples of strange SEO problems? Here are four examples to mull over while you read. We’ll answer them at the end.
1. Why wasn’t Google showing 5-star markup on product pages?
- The pages had server-rendered product markup and they also had Feefo product markup, including ratings being attached client-side.
- The Feefo ratings snippet was successfully rendered in Fetch & Render, plus the mobile-friendly tool.
- When you put the rendered DOM into the structured data testing tool, both pieces of structured data appeared without errors.
2. Why wouldn’t Bing display 5-star markup on review pages, when Google would?
- The review pages of client & competitors all had rating rich snippets on Google.
- All the competitors had rating rich snippets on Bing; however, the client did not.
- The review pages had correctly validating ratings schema on Google’s structured data testing tool, but did not on Bing.
3. Why were pages getting indexed with a no-index tag?
- Pages with a server-side-rendered no-index tag in the head were being indexed by Google across a large template for a client.
4. Why did any page on a website return a 302 about 20–50% of the time, but only for crawlers?
- A website was randomly throwing 302 errors.
- This never happened in the browser and only in crawlers.
- User agent made no difference; location or cookies also made no difference.
Finally, a quick note. It’s entirely possible that some of this checklist won’t apply to every scenario. That’s totally fine. It’s meant to be a process for everything you could check, not everything you should check.
The pre-checklist check
Does it actually matter?
Does this problem only affect a tiny amount of traffic? Is it only on a handful of pages and you already have a big list of other actions that will help the website? You probably need to just drop it.
I know, I hate it too. I also want to be right and dig these things out. But in six months' time, when you've solved twenty complex SEO rabbit holes and your website has stayed flat because you didn't re-write the title tags, you're still going to get fired.
But hopefully that's not the case, in which case, onwards!
Where are you seeing the problem?
We don’t want to waste a lot of time. Have you heard this wonderful saying?: “If you hear hooves, it’s probably not a zebra.”
The process we’re about to go through is fairly involved and it’s entirely up to your discretion if you want to go ahead. Just make sure you’re not overlooking something obvious that would solve your problem. Here are some common problems I’ve come across that were mostly horses.
- You’re underperforming from where you should be.
- When a site is under-performing, people love looking for excuses. Weird Google nonsense can be quite a handy thing to blame. In reality, it’s typically some combination of a poor site, higher competition, and a failing brand. Horse.
- You’ve suffered a sudden traffic drop.
- Something has certainly happened, but this is probably not the checklist for you. There are plenty of common-sense checklists for this. I’ve written about diagnosing traffic drops recently — check that out first.
- The wrong page is ranking for the wrong query.
- In my experience (which should probably preface this entire post), this is usually a basic problem where a site has poor targeting or a lot of cannibalization. Probably a horse.
Factors which make it more likely that you’ve got a more complex problem which require you to don your debugging shoes:
- A website that has a lot of client-side JavaScript.
- Bigger, older websites with more legacy.
- Your problem is related to a new Google property or feature where there is less community knowledge.
1. Start by picking some example pages.
Pick a couple of example pages to work with — ones that exhibit whatever problem you're seeing. No, this won't be representative, but we'll come back to that in a bit.
Of course, if it only affects a tiny number of pages then it might actually be representative, in which case we're good. It definitely matters, right? You didn't just skip the step above? OK, cool, let's move on.
2. Can Google crawl the page once?
First we’re checking whether Googlebot has access to the page, which we’ll define as a 200 status code.
We’ll check in four different ways to expose any common issues:
- Robots.txt: Open up Search Console and check in the robots.txt validator.
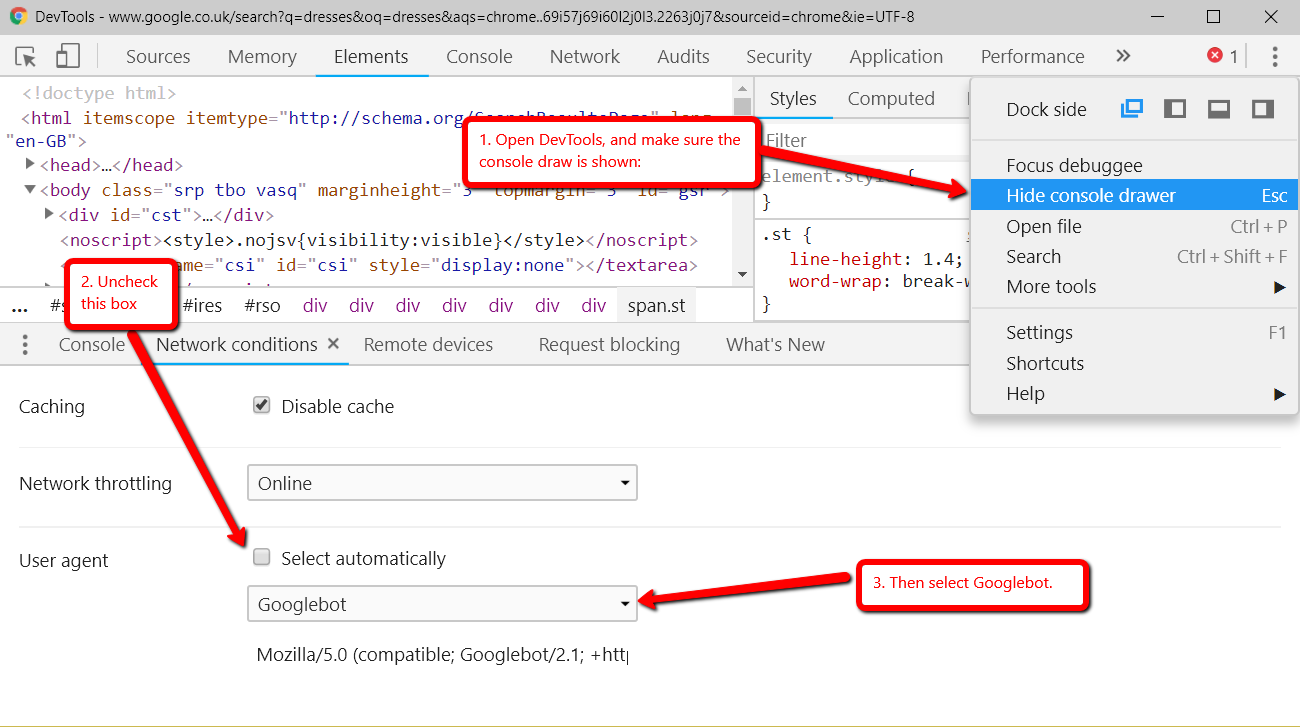
- User agent: Open Dev Tools and verify that you can open the URL with both Googlebot and Googlebot Mobile.
- To get the user agent switcher, open Dev Tools.
- Check the console drawer is open (the toggle is the Escape key)
- Hit the … and open "Network conditions"
- Here, select your user agent!
- IP Address: Verify that you can access the page with the mobile testing tool. (This will come from one of the IPs used by Google; any checks you do from your computer won't.)
- Country: The mobile testing tool will visit from US IPs, from what I've seen, so we get two birds with one stone. But Googlebot will occasionally crawl from non-American IPs, so it’s also worth using a VPN to double-check whether you can access the site from any other relevant countries.
- I’ve used HideMyAss for this before, but whatever VPN you have will work fine.
We should now have an idea whether or not Googlebot is struggling to fetch the page once.
Have we found any problems yet?
If we can re-create a failed crawl with a simple check above, then it’s likely Googlebot is probably failing consistently to fetch our page and it’s typically one of those basic reasons.
But it might not be. Many problems are inconsistent because of the nature of technology. ;)
3. Are we telling Google two different things?
Next up: Google can find the page, but are we confusing it by telling it two different things?
This is most commonly seen, in my experience, because someone has messed up the indexing directives.
By "indexing directives," I’m referring to any tag that defines the correct index status or page in the index which should rank. Here’s a non-exhaustive list:
- No-index
- Canonical
- Mobile alternate tags
- AMP alternate tags
An example of providing mixed messages would be:
- No-indexing page A
- Page B canonicals to page A
Or:
- Page A has a canonical in a header to A with a parameter
- Page A has a canonical in the body to A without a parameter
If we’re providing mixed messages, then it’s not clear how Google will respond. It’s a great way to start seeing strange results.
Good places to check for the indexing directives listed above are:
- Sitemap
- Example: Mobile alternate tags can sit in a sitemap
- HTTP headers
- Example: Canonical and meta robots can be set in headers.
- HTML head
- This is where you’re probably looking, you’ll need this one for a comparison.
- JavaScript-rendered vs hard-coded directives
- You might be setting one thing in the page source and then rendering another with JavaScript, i.e. you would see something different in the HTML source from the rendered DOM.
- Google Search Console settings
- There are Search Console settings for ignoring parameters and country localization that can clash with indexing tags on the page.
A quick aside on rendered DOM
This page has a lot of mentions of the rendered DOM on it (18, if you’re curious). Since we’ve just had our first, here’s a quick recap about what that is.
When you load a webpage, the first request is the HTML. This is what you see in the HTML source (right-click on a webpage and click View Source).
This is before JavaScript has done anything to the page. This didn’t use to be such a big deal, but now so many websites rely heavily on JavaScript that the most people quite reasonably won’t trust the the initial HTML.
Rendered DOM is the technical term for a page, when all the JavaScript has been rendered and all the page alterations made. You can see this in Dev Tools.
In Chrome you can get that by right clicking and hitting inspect element (or Ctrl + Shift + I). The Elements tab will show the DOM as it’s being rendered. When it stops flickering and changing, then you’ve got the rendered DOM!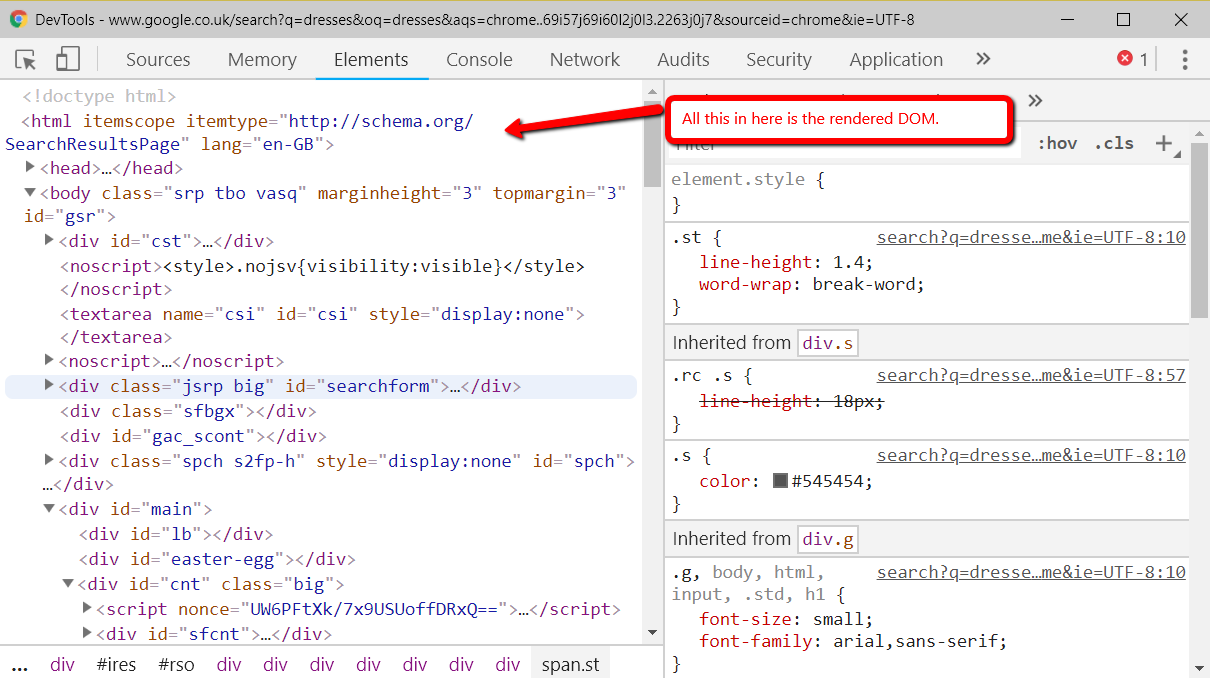
4. Can Google crawl the page consistently?
To see what Google is seeing, we're going to need to get log files. At this point, we can check to see how it is accessing the page.
Aside: Working with logs is an entire post in and of itself. I’ve written a guide to log analysis with BigQuery, I’d also really recommend trying out Screaming Frog Log Analyzer, which has done a great job of handling a lot of the complexity around logs.
When we’re looking at crawling there are three useful checks we can do:
- Status codes: Plot the status codes over time. Is Google seeing different status codes than you when you check URLs?
- Resources: Is Google downloading all the resources of the page?
- Is it downloading all your site-specific JavaScript and CSS files that it would need to generate the page?
- Page size follow-up: Take the max and min of all your pages and resources and diff them. If you see a difference, then Google might be failing to fully download all the resources or pages. (Hat tip to @ohgm, where I first heard this neat tip).
Have we found any problems yet?
If Google isn't getting 200s consistently in our log files, but we can access the page fine when we try, then there is clearly still some differences between Googlebot and ourselves. What might those differences be?
- It will crawl more than us
- It is obviously a bot, rather than a human pretending to be a bot
- It will crawl at different times of day
This means that:
- If our website is doing clever bot blocking, it might be able to differentiate between us and Googlebot.
- Because Googlebot will put more stress on our web servers, it might behave differently. When websites have a lot of bots or visitors visiting at once, they might take certain actions to help keep the website online. They might turn on more computers to power the website (this is called scaling), they might also attempt to rate-limit users who are requesting lots of pages, or serve reduced versions of pages.
- Servers run tasks periodically; for example, a listings website might run a daily task at 01:00 to clean up all it’s old listings, which might affect server performance.
Working out what’s happening with these periodic effects is going to be fiddly; you’re probably going to need to talk to a back-end developer.
Depending on your skill level, you might not know exactly where to lead the discussion. A useful structure for a discussion is often to talk about how a request passes through your technology stack and then look at the edge cases we discussed above.
- What happens to the servers under heavy load?
- When do important scheduled tasks happen?
Two useful pieces of information to enter this conversation with:
- Depending on the regularity of the problem in the logs, it is often worth trying to re-create the problem by attempting to crawl the website with a crawler at the same speed/intensity that Google is using to see if you can find/cause the same issues. This won’t always be possible depending on the size of the site, but for some sites it will be. Being able to consistently re-create a problem is the best way to get it solved.
- If you can’t, however, then try to provide the exact periods of time where Googlebot was seeing the problems. This will give the developer the best chance of tying the issue to other logs to let them debug what was happening.
If Google can crawl the page consistently, then we move onto our next step.
5. Does Google see what I can see on a one-off basis?
We know Google is crawling the page correctly. The next step is to try and work out what Google is seeing on the page. If you’ve got a JavaScript-heavy website you’ve probably banged your head against this problem before, but even if you don’t this can still sometimes be an issue.
We follow the same pattern as before. First, we try to re-create it once. The following tools will let us do that:
- Fetch & Render
- Shows: Rendered DOM in an image, but only returns the page source HTML for you to read.
- Mobile-friendly test
- Shows: Rendered DOM and returns rendered DOM for you to read.
- Not only does this show you rendered DOM, but it will also track any console errors.
Is there a difference between Fetch & Render, the mobile-friendly testing tool, and Googlebot? Not really, with the exception of timeouts (which is why we have our later steps!). Here’s the full analysis of the difference between them, if you’re interested.
Once we have the output from these, we compare them to what we ordinarily see in our browser. I’d recommend using a tool like Diff Checker to compare the two.
Have we found any problems yet?
If we encounter meaningful differences at this point, then in my experience it’s typically either from JavaScript or cookies
Why?
We can isolate each of these by:
- Loading the page with no cookies. This can be done simply by loading the page with a fresh incognito session and comparing the rendered DOM here against the rendered DOM in our ordinary browser.
- Use the mobile testing tool to see the page with Chrome 41 and compare against the rendered DOM we normally see with Inspect Element.
Yet again we can compare them using something like Diff Checker, which will allow us to spot any differences. You might want to use an HTML formatter to help line them up better.
We can also see the JavaScript errors thrown using the Mobile-Friendly Testing Tool, which may prove particularly useful if you’re confident in your JavaScript.
If, using this knowledge and these tools, we can recreate the bug, then we have something that can be replicated and it’s easier for us to hand off to a developer as a bug that will get fixed.
If we’re seeing everything is correct here, we move on to the next step.
6. What is Google actually seeing?
It’s possible that what Google is seeing is different from what we recreate using the tools in the previous step. Why? A couple main reasons:
- Overloaded servers can have all sorts of strange behaviors. For example, they might be returning 200 codes, but perhaps with a default page.
- JavaScript is rendered separately from pages being crawled and Googlebot may spend less time rendering JavaScript than a testing tool.
- There is often a lot of caching in the creation of web pages and this can cause issues.
We’ve gotten this far without talking about time! Pages don’t get crawled instantly, and crawled pages don’t get indexed instantly.
Quick sidebar: What is caching?
Caching is often a problem if you get to this stage. Unlike JS, it’s not talked about as much in our community, so it’s worth some more explanation in case you’re not familiar. Caching is storing something so it’s available more quickly next time.
When you request a webpage, a lot of calculations happen to generate that page. If you then refreshed the page when it was done, it would be incredibly wasteful to just re-run all those same calculations. Instead, servers will often save the output and serve you the output without re-running them. Saving the output is called caching.
Why do we need to know this? Well, we’re already well out into the weeds at this point and so it’s possible that a cache is misconfigured and the wrong information is being returned to users.
There aren’t many good beginner resources on caching which go into more depth. However, I found this article on caching basics to be one of the more friendly ones. It covers some of the basic types of caching quite well.
How can we see what Google is actually working with?
- Google’s cache
- Shows: Source code
- While this won’t show you the rendered DOM, it is showing you the raw HTML Googlebot actually saw when visiting the page. You’ll need to check this with JS disabled; otherwise, on opening it, your browser will run all the JS on the cached version.
- Site searches for specific content
- Shows: A tiny snippet of rendered content.
- By searching for a specific phrase on a page, e.g. inurl:example.com/url “only JS rendered text”, you can see if Google has manage to index a specific snippet of content. Of course, it only works for visible text and misses a lot of the content, but it's better than nothing!
- Better yet, do the same thing with a rank tracker, to see if it changes over time.
- Storing the actual rendered DOM
- Shows: Rendered DOM
- Alex from DeepCrawl has written about saving the rendered DOM from Googlebot. The TL;DR version: Google will render JS and post to endpoints, so we can get it to submit the JS-rendered version of a page that it sees. We can then save that, examine it, and see what went wrong.
Have we found any problems yet?
Again, once we’ve found the problem, it’s time to go and talk to a developer. The advice for this conversation is identical to the last one — everything I said there still applies.
The other knowledge you should go into this conversation armed with: how Google works and where it can struggle. While your developer will know the technical ins and outs of your website and how it’s built, they might not know much about how Google works. Together, this can help you reach the answer more quickly.
The obvious source for this are resources or presentations given by Google themselves. Of the various resources that have come out, I’ve found these two to be some of the more useful ones for giving insight into first principles:
But there is often a difference between statements Google will make and what the SEO community sees in practice. All the SEO experiments people tirelessly perform in our industry can also help shed some insight. There are far too many list here, but here are two good examples:
7. Could Google be aggregating your website across others?
If we’ve reached this point, we’re pretty happy that our website is running smoothly. But not all problems can be solved just on your website; sometimes you’ve got to look to the wider landscape and the SERPs around it.
Most commonly, what I’m looking for here is:
- Similar/duplicate content to the pages that have the problem.
- This could be intentional duplicate content (e.g. syndicating content) or unintentional (competitors' scraping or accidentally indexed sites).
Either way, they’re nearly always found by doing exact searches in Google. I.e. taking a relatively specific piece of content from your page and searching for it in quotes.
Have you found any problems yet?
If you find a number of other exact copies, then it’s possible they might be causing issues.
The best description I’ve come up with for “have you found a problem here?” is: do you think Google is aggregating together similar pages and only showing one? And if it is, is it picking the wrong page?
This doesn’t just have to be on traditional Google search. You might find a version of it on Google Jobs, Google News, etc.
To give an example, if you are a reseller, you might find content isn’t ranking because there's another, more authoritative reseller who consistently posts the same listings first.
Sometimes you’ll see this consistently and straightaway, while other times the aggregation might be changing over time. In that case, you’ll need a rank tracker for whatever Google property you’re working on to see it.
Jon Earnshaw from Pi Datametrics gave an excellent talk on the latter (around suspicious SERP flux) which is well worth watching.
Once you’ve found the problem, you’ll probably need to experiment to find out how to get around it, but the easiest factors to play with are usually:
- De-duplication of content
- Speed of discovery (you can often improve by putting up a 24-hour RSS feed of all the new content that appears)
- Lowering syndication
8. A roundup of some other likely suspects
If you’ve gotten this far, then we’re sure that:
- Google can consistently crawl our pages as intended.
- We’re sending Google consistent signals about the status of our page.
- Google is consistently rendering our pages as we expect.
- Google is picking the correct page out of any duplicates that might exist on the web.
And your problem still isn’t solved?
And it is important?
Well, shoot.
Feel free to hire us…?
As much as I’d love for this article to list every SEO problem ever, that’s not really practical, so to finish off this article let’s go through two more common gotchas and principles that didn’t really fit in elsewhere before the answers to those four problems we listed at the beginning.
Invalid/poorly constructed HTML
You and Googlebot might be seeing the same HTML, but it might be invalid or wrong. Googlebot (and any crawler, for that matter) has to provide workarounds when the HTML specification isn't followed, and those can sometimes cause strange behavior.
The easiest way to spot it is either by eye-balling the rendered DOM tools or using an HTML validator.
The W3C validator is very useful, but will throw up a lot of errors/warnings you won’t care about. The closest I can give to a one-line of summary of which ones are useful is to:
- Look for errors
- Ignore anything to do with attributes (won’t always apply, but is often true).
The classic example of this is breaking the head.
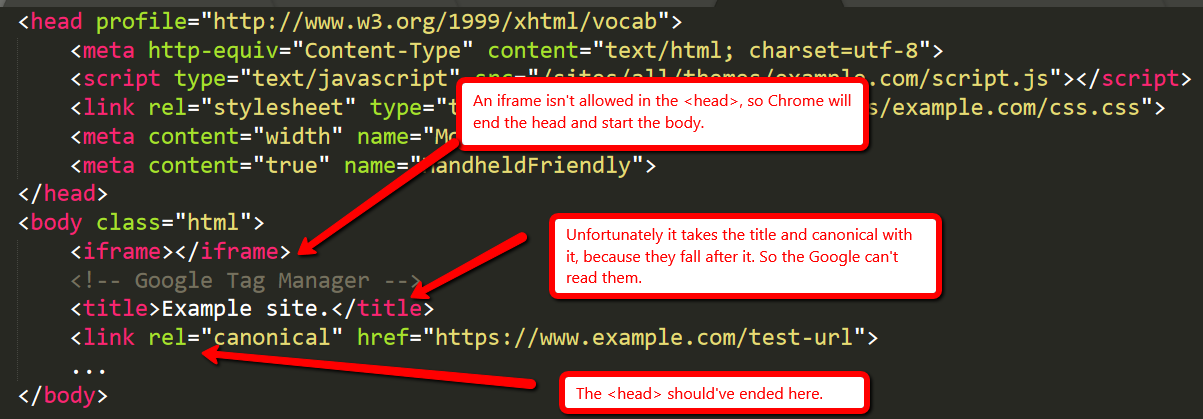
An iframe isn't allowed in the head code, so Chrome will end the head and start the body. Unfortunately, it takes the title and canonical with it, because they fall after it — so Google can't read them. The head code should have ended in a different place.
Oliver Mason wrote a good post that explains an even more subtle version of this in breaking the head quietly.
When in doubt, diff
Never underestimate the power of trying to compare two things line by line with a diff from something like Diff Checker. It won’t apply to everything, but when it does it’s powerful.
For example, if Google has suddenly stopped showing your featured markup, try to diff your page against a historical version either in your QA environment or from the Wayback Machine.
Answers to our original 4 questions
Time to answer those questions. These are all problems we’ve had clients bring to us at Distilled.
1. Why wasn’t Google showing 5-star markup on product pages?
Google was seeing both the server-rendered markup and the client-side-rendered markup; however, the server-rendered side was taking precedence.
Removing the server-rendered markup meant the 5-star markup began appearing.
2. Why wouldn’t Bing display 5-star markup on review pages, when Google would?
The problem came from the references to schema.org.
<div itemscope="" itemtype="https://schema.org/Movie">
</div>
<p> <h1 itemprop="name">Avatar</h1>
</p>
<p> <span>Director: <span itemprop="director">James Cameron</span> (born August 16, 1954)</span>
</p>
<p> <span itemprop="genre">Science fiction</span>
</p>
<p> <a href="../movies/avatar-theatrical-trailer.html" itemprop="trailer">Trailer</a>
</p>
<p></div>
</p>
We diffed our markup against our competitors and the only difference was we’d referenced the HTTPS version of schema.org in our itemtype, which caused Bing to not support it.
C’mon, Bing.
3. Why were pages getting indexed with a no-index tag?
The answer for this was in this post. This was a case of breaking the head.
The developers had installed some ad-tech in the head and inserted an non-standard tag, i.e. not:
- <title>
- <style>
- <base>
- <link>
- <meta>
- <script>
- <noscript>
This caused the head to end prematurely and the no-index tag was left in the body where it wasn’t read.
4. Why did any page on a website return a 302 about 20–50% of the time, but only for crawlers?
This took some time to figure out. The client had an old legacy website that has two servers, one for the blog and one for the rest of the site. This issue started occurring shortly after a migration of the blog from a subdomain (blog.client.com) to a subdirectory (client.com/blog/…).
At surface level everything was fine; if a user requested any individual page, it all looked good. A crawl of all the blog URLs to check they’d redirected was fine.
But we noticed a sharp increase of errors being flagged in Search Console, and during a routine site-wide crawl, many pages that were fine when checked manually were causing redirect loops.
We checked using Fetch and Render, but once again, the pages were fine.
Eventually, it turned out that when a non-blog page was requested very quickly after a blog page (which, realistically, only a crawler is fast enough to achieve), the request for the non-blog page would be sent to the blog server.
These would then be caught by a long-forgotten redirect rule, which 302-redirected deleted blog posts (or other duff URLs) to the root. This, in turn, was caught by a blanket HTTP to HTTPS 301 redirect rule, which would be requested from the blog server again, perpetuating the loop.
For example, requesting https://www.client.com/blog/ followed quickly enough by https://www.client.com/category/ would result in:
- 302 to http://www.client.com - This was the rule that redirected deleted blog posts to the root
- 301 to https://www.client.com - This was the blanket HTTPS redirect
- 302 to http://www.client.com - The blog server doesn’t know about the HTTPS non-blog homepage and it redirects back to the HTTP version. Rinse and repeat.
This caused the periodic 302 errors and it meant we could work with their devs to fix the problem.
What are the best brainteasers you've had?
Let’s hear them, people. What problems have you run into? Let us know in the comments.
Also credit to @RobinLord8, @TomAnthonySEO, @THCapper, @samnemzer, and @sergeystefoglo_ for help with this piece.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!







 Crawling with a tool
Crawling with a tool

{kind=link}